2022. 8. 24. 01:21ㆍ알고리즘/programmers
안녕하세요!
프로그래머스가 2022 카카오 인턴 코딩테스트 문제를 풀어줬네요.
일단 등산코스부터 한번 볼까 합니다.
이 문제는 다익스트라(dijkstra) 알고리즘을 활용해야하는 문제입니다.
문제를 읽기 전에 먼저 다익스트라 알고리즘에 대해 알아볼 필요가 있겠네요.
다익스트라(Dijkstra) 알고리즘: 간선에 가중치(weight)가 달라질 때..
아래와 같은 그래프가 있다고 해볼까요?
간선에 적힌 노란 숫자는 그 노드로 가기까지 필요한 가중치(weight)라고 합니다.
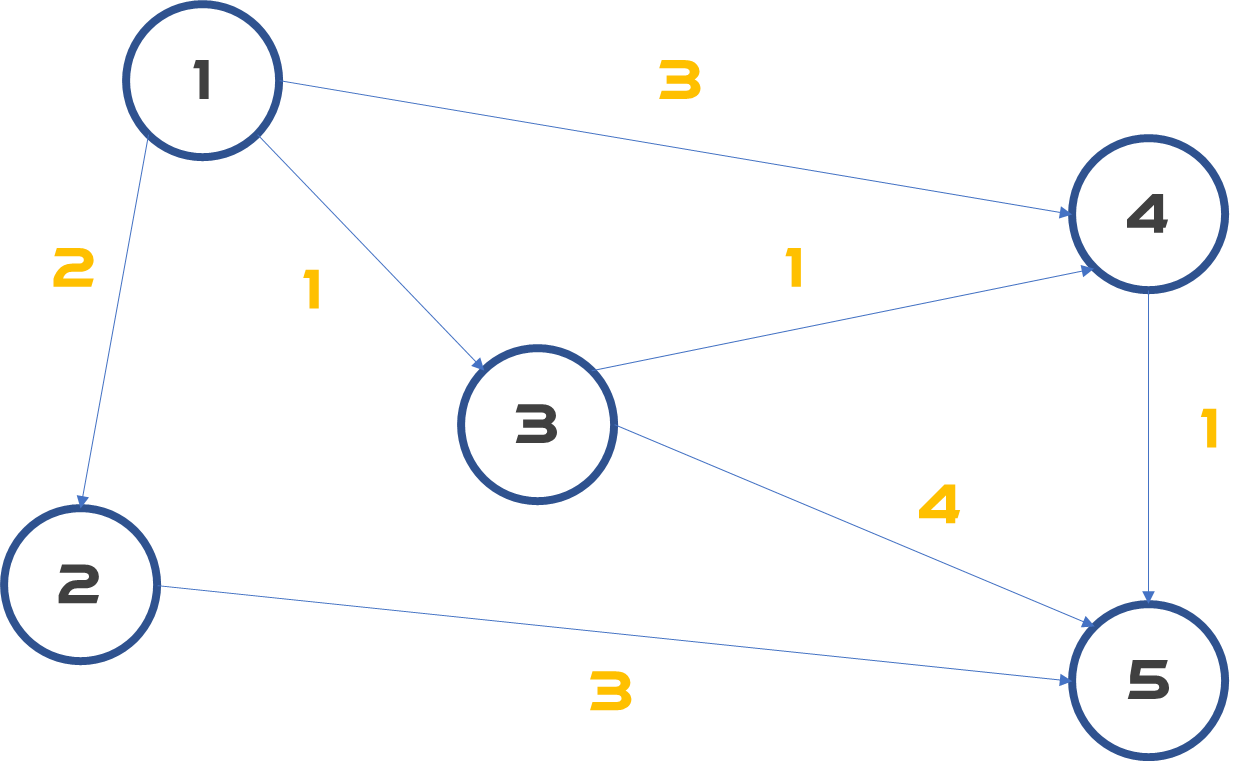
가중치가 있는 경로에서는 bfs를 사용할 수 없습니다.
왜냐면 visited를 관리할 수 없기 때문입니다.
일반적인 bfs라면 노드 1에서 5를 향해 출발 할때 노드 4를 방문 처리하지만, 여긴 다릅니다.
가중치가 있기 때문에 노드 4를 우선 3으로 초기화 한 다음에 노드 3을 거쳐가는 방법이 더 빠르다는 걸 알게 되면 갱신해줍니다. 결론적으로 이미 간 노드인 노드4를 두 번 방문해야하는 셈이죠.
visited를 number로 관리하는 순간, 사이클 문제를 해결할 수가 없게 됩니다.
그래서 다익스트라 알고리즘에서는 우선순위 큐로 이 문제를 해결합니다.
1. 노드 1에 연결되어 있는 노드를 방문.

노드 1에서 출발한다면, 노드 2, 3, 4를 갱신해줄 수 있습니다.
그리고 이 모든 노드를 우선순위 큐(최소 힙)에 넣어줍니다.
여기서 중요한 다익스트라의 성질이 있습니다.
이전 노드가 최소 경로임이 보장된다면, 그 노드의 다음경로또한 최소 경로임이 보장된다.
어떻게 보면 당연한 이야기네요. 그러나 중요합니다.
우리가 눈대중으로 대충 보면 1-3-4-5 경로가 3으로 가장 짧다는 걸 알 수 있습니다.
노드 4까지 오는 최소 경로인 2가 보장되는 순간, 노드 5로 가는 경로 역시 확정적으로 정할 수 있습니다.
2. 우선순위 큐를 pop하고, 그 노드와 연결된 노드를 순회.

우선순위 큐는 지금 가장 작은 값을 가장 먼저 오도록 정렬해줍니다.
(편의 상, length가 같아도 순서가 바뀐다고 가정하겠습니다. 일반적으로 불안정 정렬이라 선호되지 않습니다.)
운 좋게도, 바로 노드 4를 최소로 만드는 경로를 먼저 왔네요. 꼭 이렇지는 않습니다.
3. 우선 순위 큐를 모두 순회합니다.
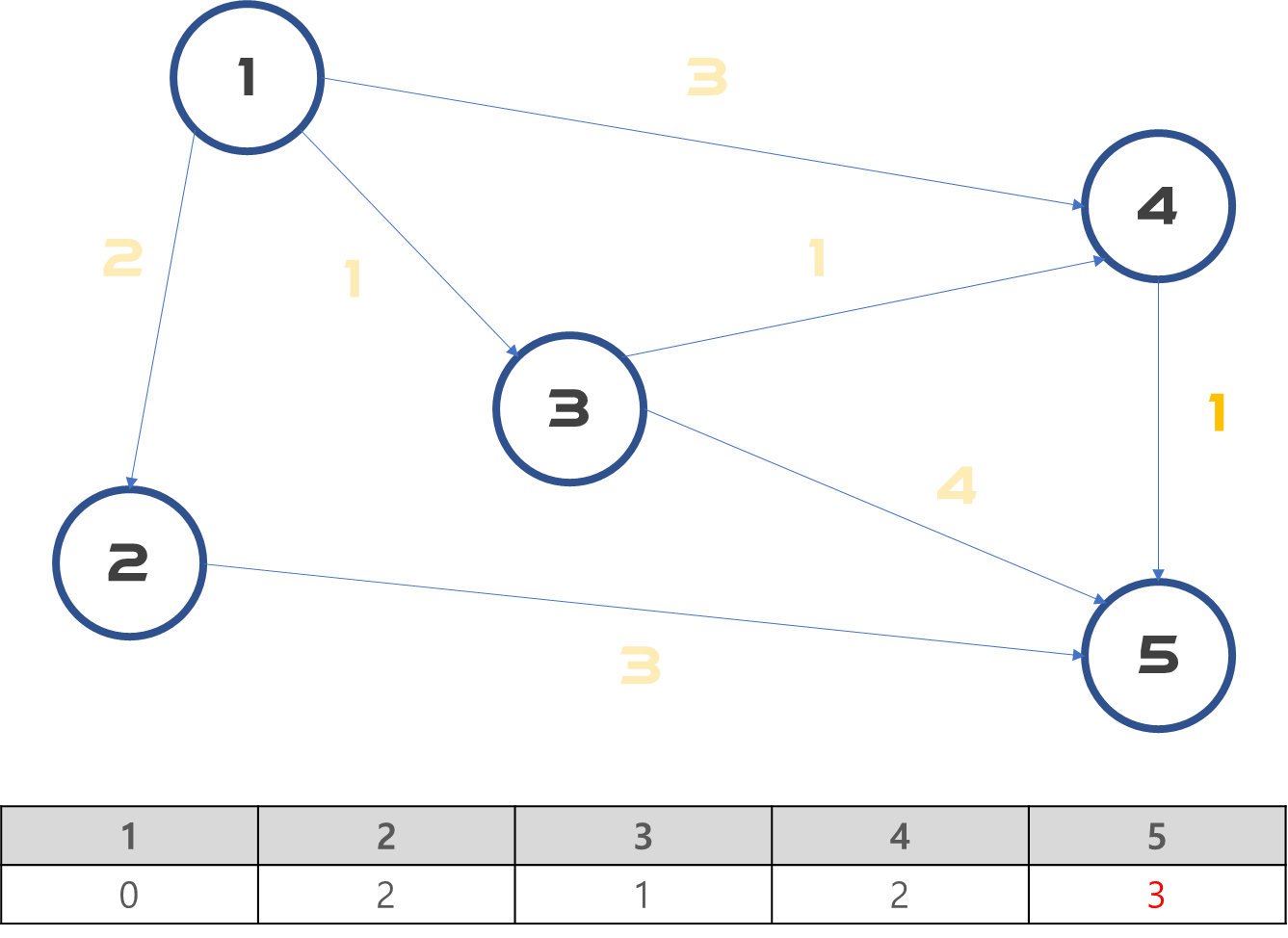
모든 우선 순위 큐를 pop 해서, length와 표에 적힌 최소 길이와 비교하면서 표를 완성해줍니다.
결론적으로 모든 노드를 최소 길이로 도착하는 표를 얻어낼 수 있었네요.
이번에 우리가 시도할 등산 코스 정하기 문제도 다익스트라 알고리즘으로 접근하면 보다 편합니다.
문제 요약
XX산은 n개의 지점으로 이루어져 있습니다. 각 지점은 1부터 n까지 번호가 붙어있으며, 출입구, 쉼터, 혹은 산봉우리입니다. 각 지점은 양방향 통행이 가능한 등산로로 연결되어 있으며, 서로 다른 지점을 이동할 때 이 등산로를 이용해야 합니다. 이때, 등산로별로 이동하는데 일정 시간이 소요됩니다.
등산코스는 방문할 지점 번호들을 순서대로 나열하여 표현할 수 있습니다.
예를 들어 1-2-3-2-1 으로 표현하는 등산코스는 1번지점에서 출발하여 2번, 3번, 2번, 1번 지점을 순서대로 방문한다는 뜻입니다.
등산코스를 따라 이동하는 중 쉼터 혹은 산봉우리를 방문할 때마다 휴식을 취할 수 있으며, 휴식 없이 이동해야 하는 시간 중 가장 긴 시간을 해당 등산코스의 intensity라고 부르기로 합니다.
당신은 XX산의 출입구 중 한 곳에서 출발하여 산봉우리 중 한 곳만 방문한 뒤 다시 원래의 출입구로 돌아오는 등산코스를 정하려고 합니다. 다시 말해, 등산코스에서 출입구는 처음과 끝에 한 번씩, 산봉우리는 한 번만 포함되어야 합니다.
당신은 이러한 규칙을 지키면서 intensity가 최소가 되도록 등산코스를 정하려고 합니다.
다음은 XX산의 지점과 등산로를 그림으로 표현한 예시입니다.
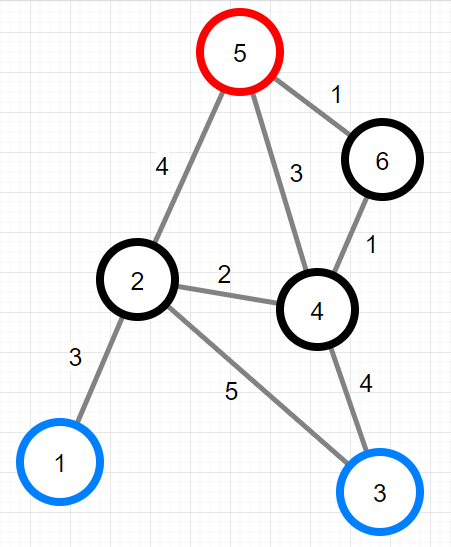
- 위 그림에서 원에 적힌 숫자는 지점의 번호를 나타내며, 1, 3번 지점에 출입구, 5번 지점에 산봉우리가 있습니다. 각 선분은 등산로를 나타내며, 각 선분에 적힌 수는 이동 시간을 나타냅니다. 예를 들어 1번 지점에서 2번 지점으로 이동할 때는 3시간이 소요됩니다.
위의 예시에서 1-2-5-4-3 과 같은 등산코스는 처음 출발한 원래의 출입구로 돌아오지 않기 때문에 잘못된 등산코스입니다. 또한 1-2-5-6-4-3-2-1 과 같은 등산코스는 코스의 처음과 끝 외에 3번 출입구를 방문하기 때문에 잘못된 등산코스입니다.
등산코스를 3-2-5-4-3 과 같이 정했을 때의 이동경로를 그림으로 나타내면 아래와 같습니다.

이때, 휴식 없이 이동해야 하는 시간 중 가장 긴 시간은 5시간입니다. 따라서 이 등산코스의 intensity는 5입니다.
등산코스를 1-2-4-5-6-4-2-1 과 같이 정했을 때의 이동경로를 그림으로 나타내면 아래와 같습니다.

이때, 휴식 없이 이동해야 하는 시간 중 가장 긴 시간은 3시간입니다. 따라서 이 등산코스의 intensity는 3이며, 이 보다 intensity가 낮은 등산코스는 없습니다.
XX산의 지점 수 n, 각 등산로의 정보를 담은 2차원 정수 배열 paths, 출입구들의 번호가 담긴 정수 배열 gates, 산봉우리들의 번호가 담긴 정수 배열 summits가 매개변수로 주어집니다. 이때, intensity가 최소가 되는 등산코스에 포함된 산봉우리 번호와 intensity의 최솟값을 차례대로 정수 배열에 담아 return 하도록 solution 함수를 완성해주세요. intensity가 최소가 되는 등산코스가 여러 개라면 그중 산봉우리의 번호가 가장 낮은 등산코스를 선택합니다.
제한사항
- 2 ≤ n ≤ 50,000
- n - 1 ≤ paths의 길이 ≤ 200,000
- paths의 원소는 [i, j, w] 형태입니다.
- i번 지점과 j번 지점을 연결하는 등산로가 있다는 뜻입니다.
- w는 두 지점 사이를 이동하는 데 걸리는 시간입니다.
- 1 ≤ i < j ≤ n
- 1 ≤ w ≤ 10,000,000
- 서로 다른 두 지점을 직접 연결하는 등산로는 최대 1개입니다.
- 1 ≤ gates의 길이 ≤ n
- 1 ≤ gates의 원소 ≤ n
- gates의 원소는 해당 지점이 출입구임을 나타냅니다.
- 1 ≤ summits의 길이 ≤ n
- 1 ≤ summits의 원소 ≤ n
- summits의 원소는 해당 지점이 산봉우리임을 나타냅니다.
- 출입구이면서 동시에 산봉우리인 지점은 없습니다.
- gates와 summits에 등장하지 않은 지점은 모두 쉼터입니다.
- 임의의 두 지점 사이에 이동 가능한 경로가 항상 존재합니다.
- return 하는 배열은 [산봉우리의 번호, intensity의 최솟값] 순서여야 합니다.
테스트케이스
| n | paths | gates | summits | result |
| 6 | [[1, 2, 3], [2, 3, 5], [2, 4, 2], [2, 5, 4], [3, 4, 4], [4, 5, 3], [4, 6, 1], [5, 6, 1]] | [1, 3] | [5] | [5, 3] |
| 7 | [[1, 4, 4], [1, 6, 1], [1, 7, 3], [2, 5, 2], [3, 7, 4], [5, 6, 6]] | [1] | [2, 3, 4] | [3, 4] |
| 7 | [[1, 2, 5], [1, 4, 1], [2, 3, 1], [2, 6, 7], [4, 5, 1], [5, 6, 1], [6, 7, 1]] | [3, 7] | [1, 5] | [5, 1] |
| 5 | [[1, 3, 10], [1, 4, 20], [2, 3, 4], [2, 4, 6], [3, 5, 20], [4, 5, 6]] | [1, 2] | [5] | [5, 6] |
접근 방법
먼저, 다익스트라 특성 "이전 노드가 최소가 보장된다면, 다음 노드 역시 최소이다."
=> 이 특성에 의해 내려오는 경로는 생각할 필요가 없습니다. 이미 최소 경로로 올라갔다면, 그대로 타고 내려오는게 가장 intensity를 최소로 산을 내려가는 방법임이 보장됩니다.
다익스트라 알고리즘을 알아보면서 우린 이 알고리즘이 목적 노드에 관계없이 모든 노드를 최솟값으로 갱신해준다는 걸 알아냈습니다.
=> 이 말은 결국, summits의 갯수에 상관없이 최솟값으로 갱신된다는 말이겠네요.
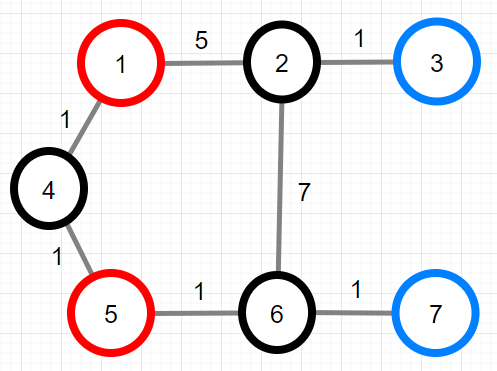
다만, 위의 입출력 예시 #3과 같이 summits에 여러 번 접근은 안되니, summits 노드에 왔다면 멈춰야겠네요.
이전의 다익스트라 알고리즘은 우리가 방문하는 모든 길이를 더해주는 용도로 사용했었습니다.
이번에는 경로 중 가장 최댓값을 써야하겠네요.
// 만약 길이를 더하는 다익스트라였다면?
const nextVal = prevLength + nextLength;
if (nextVal < minLenList[current]) {
minLenList[current] = nextVal;
heap.enqueue({ node: next, val: nextVal });
}
// 이번에 쓰일 최댓값을 구하는 다익스트라라면?
const nextVal = Math.max(prevLength, nextLength);
if (nextVal < minLenList[current]) {
minLenList[current] = nextVal;
heap.enqueue({ node: next, val: nextVal });
}
이렇게 구성해주면 됩니다.
자 그럼 정답 코드를 볼까요?
정답 코드
class Queue {
constructor() {
this.queue = [];
this.front = 0;
this.rear = 0;
}
enqueue(val) {
this.queue[this.rear++] = val;
}
dequeue() {
const val = this.queue[this.front];
delete this.queue[this.front++];
return val;
}
isEmpty() {
return this.front === this.rear;
}
}
function solution(n, paths, gates, summits) {
summits.sort((a, b) => a - b);
const heap = new Queue();
const pathMap = new Map();
const summitMap = new Map();
const gateMap = new Map();
const intensity = Array.from({length: n + 1}, () => 10000001);
intensity[0] = 0;
for (const summit of summits) {
summitMap.set(summit, true);
}
// gate 시작점 intensity 0으로 초기화 후 최소힙에 넣어줌.
for (const gate of gates) {
gateMap.set(gate, true);
heap.enqueue({ node: gate, intensity: 0 });
intensity[gate] = 0;
}
// path 순회 방지를 위한 해시맵 생성.
for (const [node1, node2, intensity] of paths) {
if (pathMap.has(node1)) {
const next = pathMap.get(node1);
next[next.length] = [node2, intensity];
pathMap.set(node1, next);
} else {
pathMap.set(node1, [[node2, intensity]]);
}
if (pathMap.has(node2)) {
const next = pathMap.get(node2);
next[next.length] = [node1, intensity];
pathMap.set(node2, next);
} else {
pathMap.set(node2, [[node1, intensity]]);
}
}
while (!heap.isEmpty()) {
const { node: current, intensity: currIntensity } = heap.dequeue();
if (summitMap.has(current)) continue;
const nexts = pathMap.get(current);
for (const [next, nextIntensity] of nexts) {
const maxIntensity = Math.max(currIntensity, nextIntensity);
if (maxIntensity < intensity[next]) {
intensity[next] = maxIntensity;
heap.enqueue({ node: next, intensity: maxIntensity });
}
}
}
// intensity 최솟값 기준 선정렬, node 기준 후정렬
return intensity
.filter((v, i) => (summitMap.has(i)))
.map((v, i) => [summits[i], v])
.sort((a, b) => a[1] - b[1])
.filter((v, _, arr) => v[1] === arr[0][1])
.sort((a, b) => a[0] - b[0])[0];
}
팁 1. 왜 최소 힙을 안쓰고 그냥 큐를 썼나요?
이건 js의 문제인지.. 제 코드가 문제인건지..
최소 힙으로 루프를 돌리면, 마지막 테스트 케이스 25번이 시간 초과가 나는 버그가 있었습니다.
요소를 pop하고 push하는 일이 많은데, heap은 그 때마다 정렬을 해주기 때문에 일반적인 큐보단 더 자원을 쓰게 됩니다.
그래서 혹시나 하는 마음에 일반 큐를 사용해봤는데, 왠걸.. 그냥 통과가 되더라구요.
흠... 약간 찜찜하지만 일단 큐를 써서 해결했습니다.
팁 2. 해시맵은 꼭 만들어주세요 제발...
// summitsMap 만들기. 꼭대기라면 true를 return.
for (const summit of summits) {
summitMap.set(summit, true);
}
// path 순회 방지를 위한 해시맵 생성.
for (const [node1, node2, intensity] of paths) {
if (pathMap.has(node1)) {
const next = pathMap.get(node1);
next[next.length] = [node2, intensity];
pathMap.set(node1, next);
} else {
pathMap.set(node1, [[node2, intensity]]);
}
if (pathMap.has(node2)) {
const next = pathMap.get(node2);
next[next.length] = [node1, intensity];
pathMap.set(node2, next);
} else {
pathMap.set(node2, [[node1, intensity]]);
}
}다익스트라 알고리즘 특성상, 매 노드에서 다음 노드를 찾기 위해서 paths를 순회하고,
이 문제 특성상 매 노드가 꼭대기 인지 확인해줘야합니다. (꼭대기는 한 번만 갈 수 있으니까요. 입출력 예시 #3 참고)
다만, paths의 길이는 최대 1,000,000개이고, summits는 최대 n(50,000)개이기 때문에, 그냥 처음에 한 번 돌려서 hashMap을 만들어주면 O(1)의 시간 복잡도로 접근할 수 있습니다.
팁 3. intensity 배열에서 [node, intensity] 만드는 방법
// intensity 최솟값 기준 선정렬, node 기준 후정렬
return intensity
.filter((v, i) => (summitMap.has(i)))
// intensity에서 꼭대기 노드만 추출됨.(오름차순)
.map((v, i) => [summits[i], v])
// [노드, intensity]로 새로 만들어짐.
.sort((a, b) => a[1] - b[1])
// intensity 기준으로 한 번 정렬됨.
.filter((v, _, arr) => v[1] === arr[0][1])
// intensity가 최소인 element 추출됨.
.sort((a, b) => a[0] - b[0])[0];
// intensity 최소인 노드 중에서 node번호 순으로 정렬. 0번째가 가장 작음.고차함수를 잘 쓰면 뭐든 해준다구!
생각보다 빨리 해결했는데 테스트 케이스 25번을 계속 못풀고 있었어서 계속 고민했네요.
설마 큐가 문제였을 줄이야.... 꼭 다익스트라 문제를 풀 때 힙을 안써도 된다는 교훈이 있었네요.
그럼 이만!
'알고리즘 > programmers' 카테고리의 다른 글
| [JS] 불량 사용자: 정규 표현식을 내 맘대로 써보자! (0) | 2022.08.27 |
|---|---|
| [JS] 보석 쇼핑: 효율성을 어거지로 통과하는 방법 (0) | 2022.08.25 |
| [JS] 전력망을 둘로 나누기 - bfs에서 약간만 응용해보자! (0) | 2022.08.20 |
| [JS] 표 편집 - 양방향 연결리스트(Linked List)를 사용해보자! (0) | 2022.08.18 |
| [JS] 셔틀버스 - 시간을 비교할땐 항상 조심하자! (0) | 2022.08.16 |